For this article we’re going to go through building a small application with uses Lucene.Net as a storage model. I read a lot of blogs so I’m often find that when I’m working I want to refer back to a blog that I read in the past. The problem is that finding that particular blog can be tricky, navigating through a few thousand posts can be fairly tedious. So let’s build an application which we can quickly search and find the posts that I’m interested in.
##Designing for Lucene
Although Lucene is a Document Database it’s also a search engine. This means that Lucene can actually be used as a mid-point in the application you’re designing. This can be used to turn our data for the UI without having to go to your underlying data store. This can provide speed boosts (and generally does) if you’re using Lucene well.
##To Store or not to Store…
So I’m wanting a way which I can quickly find blogs which are matching particular search terms, but I want it to be fast and I want it to be small. The blog posts are available on the web, so I can access them if/ when I need, but do I really need to have my application showing all the data too? I don’t think so, it would mean that my application needs to act a bit like a web browser, and this seems to be a bit silly. It also adds a dependency which I don’t really want in my application.
Well this means that I don’t really need to store much data at all, I just need to store the indexes! Now all I need to work out is what I want to show on my UI.
I’ve decided that I want only a very basic little UI, I just want to have a link to the article and the name of it. This means that I can save some space by not storing the content of the blog post in my index, after all, if you want to read the content you’re going out to the web.
This kind of split approach with Lucene is a common way to use Lucene. When working with Lucene the most performance intensive part of the process is actually getting the data back out of the index. Searching against Lucene is really fast, it’s what Lucene is designed for. So we have Lucene to mainly just store our analyzed version of our data, and then we have our underlying data store to retrieve all of the data.
##Building the BlogManager
I’m going to be making this little application using WPF (yep, the web developer is trying WPF, and it’s going… ok :P). First off I want a way to add RSS feeds to be able to search against:
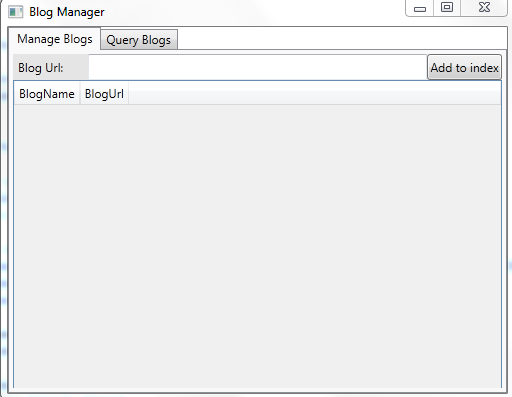
So there we go, we’re able to provide the URL for a blog and we’re going to push some data into our index. I’m actually using Lucene to store the URL’s as well as the actual blogs to search against. Remember that a Document Database doesn’t have a schema, so you can stick anything in there that you want. Let’s see some code:
public MainWindow()
{
InitializeComponent();
var path = new DirectoryInfo(Path.Combine(new FileInfo(Assembly.GetExecutingAssembly().Location).Directory.FullName, "LuceneIndex"));
if (!path.Exists)
{
path.Create();
path.Refresh();
}
this.directory = new SimpleFSDirectory(path);
this.analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_29);
this.writer = new IndexWriter(directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED);
this.searcher = new IndexSearcher(directory, true);
}
This is just my setup method, and I’m setting up a few default objects which I want to persist within my application. I’m using the StandardAnalyzer (here’s more info on analyzers) and the SimpleFSDirectory as my storage model. It’s all just setup, not very interesting code, but it can’t hurt to show you this stuff :P.
To get the data from the feed I’m using the SyndicationFeed from the .NET framework, but you could parse the XML yourself, or use any other library if you really wanted, but this done a good enough job for what I need. You just use it like this:
XmlReader xmlReader = XmlReader.Create(url);
var feed = SyndicationFeed.Load(xmlReader);
Now lets put our data into the index:
var doc = new Document();
doc.Add(new Field("name", feed.Title.Text, Field.Store.YES, Field.Index.NO));
doc.Add(new Field("url", url, Field.Store.YES, Field.Index.NO));
doc.Add(new Field("type", "BlogUrl", Field.Store.NO, Field.Index.ANALYZED));
writer.AddDocument(doc);
For this I’m storing the title of the feed and the URL of it, this is because I’m wanting to show them in a data grid (so I can get an overview of what feeds I’m indexing). And since I don’t want to be searching this data I’m leaving it unindexed. But so I can easily find this data I’m adding a meta-data property, in the form of the type field. This is something that is just meta data, so I don’t want to display it, but I do need to be able to search on it. That’s why I’m leaving it unstored and analyzed. Lastly I add this to my IndexWriter instance and we’re nearly done.
Next we need to push in the blogs which we’ve found from here:
foreach (var item in feed.Items)
{
doc = new Document();
doc.Add(new Field("title", item.Title.Text, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("content", StripHtml(item.Summary.Text), Field.Store.NO, Field.Index.ANALYZED));
doc.Add(new Field("categories", string.Join(" ", item.Categories.Select(x => x.Name)), Field.Store.NO, Field.Index.ANALYZED));
doc.Add(new Field("url", item.Links.First().Uri.ToString(), Field.Store.YES, Field.Index.NO));
doc.Add(new Field("type", "BlogPost", Field.Store.NO, Field.Index.ANALYZED));
writer.AddDocument(doc);
}
Here is pretty much the same as what we had previously, we’re just grabbing some properties and then putting them into the Document which is then written to the index. I’m setting a no-store on the content of the post and it’s categories since these are just things that I’m going to be searching against, but not ever showing it on the UI.
Now we just do a commit to our index:
writer.Commit();
Our blog has been added into our index, woo! Now it’ll be listed below in the data grid:
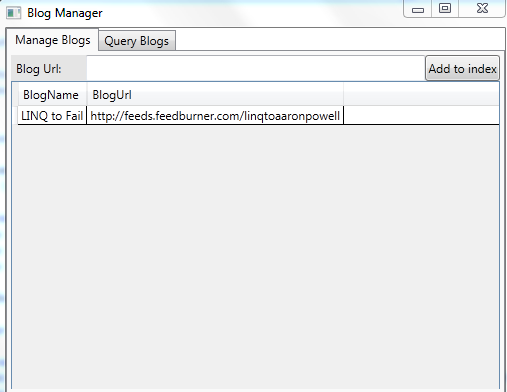
##Searching the blogs
Now that we’ve got some stuff in our index let’s try and get at it. I’ve got another awesome example of UI design for that:
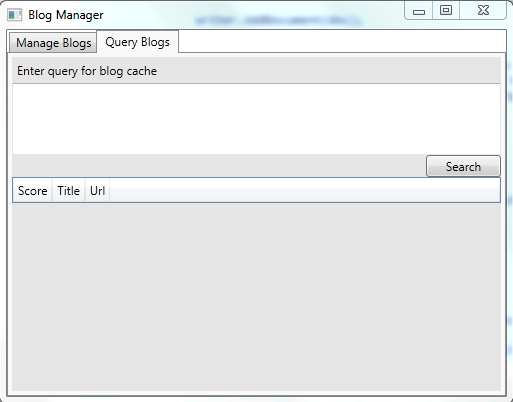
Here I’ve got a big text box which I can enter a Lucene query using the Lucene Query Parser Syntax so I can just get at the data. Lets say that I want all the posts which had Umbraco in the title:
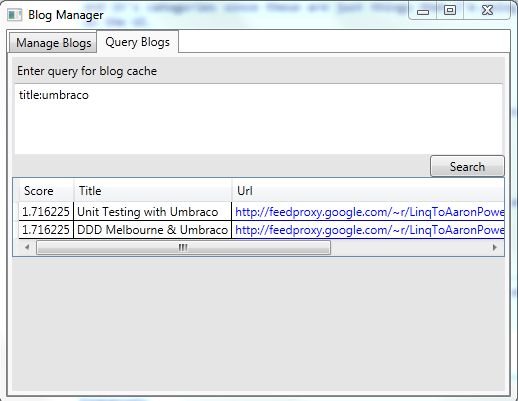
Or maybe I’ll get all the ones which contain Umbraco or Lucene.Net:
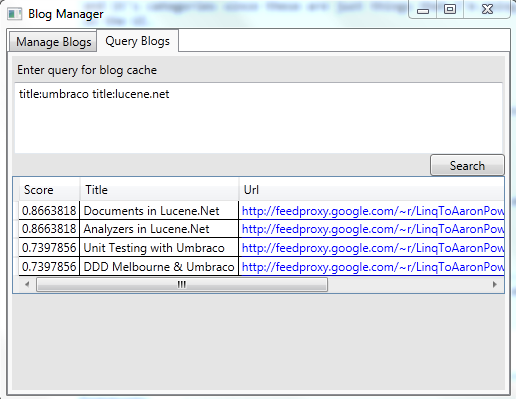
And here’s the underlying code:
var queryParser = new MultiFieldQueryParser(Version.LUCENE_29, new[] { "title", "content", "categories", "type" }, analyzer);
var query = new BooleanQuery();
query.Add(queryParser.Parse(this.QueryText.Text), BooleanClause.Occur.MUST);
query.Add(queryParser.GetFieldQuery("type", "blogpost"), BooleanClause.Occur.MUST);
var results = searcher.Search(query, null, searcher.MaxDoc());
It’s quite simple actually, I’m creating a [MultiFieldQueryParser][11] since the user may be searching across multiple different fields in the index. I’m specifying the fields which I defined earlier then taking the text which the user entered and parsing that into a Query object. I’m also doing a addition of the type field, so the actual query that you’ll end up with actually looks like this:
+(title:umbraco) +type:blogpost
I’m actually wrapping any query the user puts in so that I can postfix the type query but not override anything that they are supplying (ie - any OR conditionals will be cancelled out if the AND for the type is used).
I’m not supporting paging in the datagrid so I’m just getting back all the results. This is not recommended as it will put a lot more strain on the Lucene index than is really needed. You should only request the number of documents you actually require.
And all that’s left is to hydrate the entities:
results.scoreDocs.Select(x =>
{
var doc = searcher.Doc(x.doc);
return new
{
Title = doc.Get("title"),
Url = doc.Get("url"),
Score = x.score
};
});
Then you can push that onto your UI to get the lovely results we saw earlier.
##Conclusion
This is a very quick look at how you can use Lucene.Net to make an application that actually works across multiple data stores. Here I’m using a Lucene index for nothing but searching. I’m pushing data into it but really the end result display is all handled by my other data store, web servers.
I’ll publish the source code in a little while, along with a downloadable version of this application, but at the moment there’s a few things I need to do, like updating the index as new posts are added and properly binding the data to the UI :P.
But hopefully this gives you a view at how you can use Lucene in your own applications.