One of the main reasons I blog is to write stuff down that I have learnt so that in the future I can come back to it rather than having to keep it all in memory. The bonus is that others who come across the same problem can see how I’ve gone about solving it, so it’s a win-win. But when I converted my site to a static website it meant I had to sacrifice a piece of functionality, search. Now sure, we have pretty decent search engines out there in Google and Bing, which is what I tend to use, but I always thought that it’d be nice to integrate it back in someday.
In years gone by I’ve done work with Lucene.NET, particularly around its integration with Umbraco, and I’ve read Lucene in Action several times, so I was always thinking “wouldn’t it be cool to put Lucene on my site”. But Lucene is written in Java, Lucene.NET is… well… .NET and none of the JavaScript implementations are as feature complete as I’d like, so it was just something on the back burner… until now!
Blazor
After some conversations at a recent conference, I decided it was time to give Blazor another look. I’d played around with it in the past but nothing more than poking the Hello World demos, so I decided to try something a bit more complex.
If you’ve not come across Blazor before, Blazor is a tool for building web UI’s using C# and Razor and with the release of .NET 3.0 Blazor Server went GA. Blazor Server works by generating the HTML on the server and pushing it down to the browser using SignalR then handling all the JavaScript interop for you. You can wire up JavaScript events through C# and build a dynamic web application without writing a single line of JavaScript!
While Blazor Server is cool I’m interested in the other style of Blazor, Blazor WebAssembly. The WebAssembly (WASM) version of Blazor is in preview at the time of writing and will need you to install the .NET Core 3.1 preview build (I’m using Preview 3). The difference from Blazor Server is that rather than running a server connection with SignalR and generating the HTML server-side we compile our .NET application down with a WASM version of the Mono runtime which is then run entirely in the browser. This is perfect for my static blog and I end up with something that’s just HTML, CSS and JavaScript… wait, actually it’s a bit of JavaScript, some WASM byte code and .NET DLLs!
Creating Our Search App
Let’s have a look at what it would take to make a search app using Lucene.NET as the engine. For the time being, we’ll create it separately from the static website but in a future post we’ll look to integrate it in.
Step 1 - Creating Searchable Content
We’re going to need some content to search from somewhere, and how you get that will depend on what kind of system you’re integrating with. Maybe you’ll be pulling some data from a database about products, maybe there’s a REST API to call or in my case, I have ~400 blog posts (and climbing!) that I want to index.
The easiest way for me to make this happen is to generate a machine-parsable version of my blog posts, which I’ll do in the form of JSON (I already have XML for my RSS feed, but parsing JSON is a lot easier in .NET) so Hugo needs to be updated to support that.
First up, JSON needs to be added to Hugo’s output in the config.toml for the site:
| |
Then we can create a layout to generate the JSON in your sites layout folder:
{
"posts": [
{{ range $i, $e := where (.Data.Pages) ".Params.hidden" "!=" true }}
{{- if and $i (gt $i 0) -}},{{- end }}{
"title": {{ .Title | jsonify }},
"url": "{{ .Permalink }}",
"date": "{{ .Date.Format "Mon, 02 Jan 2006 15:04:05 -0700" | safeHTML }}",
"tags": [{{ range $tindex, $tag := $e.Params.tags }}{{ if $tindex }}, {{ end }}"{{ $tag| htmlEscape }}"{{ end }}],
"description": {{ .Description | jsonify }},
"content": {{$e.Plain | jsonify}}
}
{{ end }}
]
}
I found this template online and it iterates over all visible posts to create a JSON array that looks like this (my blog is ~2mb of JSON!):
| |
Step 2 - Setting Up Blazor
As I mentioned above you’ll need to have .NET Core 3.1 SDK installed to use Blazor WebAssembly and I’m using Preview 3 (SDK 3.1.100-preview3-014645 to be specific).
Let’s start by creating a solution and our Blazor project:
| |
The Blazor project, Search.Site.UI will contain just the .razor files and bootstrapping code, the rest of the logic will be pushed into a separate class library, Search.Site that I’m writing in F#.
Note: There is a full F#-over-Blazor project called Bolero but it’s using an outdated version of Blazor. I’m also not a huge fan of F#-as-HTML like you get with Bolero, I prefer the Razor approach to binding so I’ll do a mixed-language solution.
Now we can delete the Blazor sample site by removing everything from the Pages and Shared folder, since we’re going to create it all ourselves, with an empty default page called Index.razor:
| |
And a primitive MainLayout.razor (in the Shared folder):
| |
You might be wondering why the MainLayout.razor is so basic, the reason is that when it does come time to integrate it into our larger site we want the Blazor app to inject the minimal amount of HTML and styling, and instead use that from the hosting site, but for today we’ll get some of that from the wwwroot/index.html file.
Step 3 - Starting Our Blazor UI
Let’s build out the UI for search before we worry about the pesky backend. We’ll have the UI handle a few things, first it’ll show a message while the search index is being built (basically a loading screen), once the index is built it will present a search box and when a search is performed it’ll show the results.
In Blazor we use Components for pages (and for things we put on a page, but custom components are beyond the scope of what I’ll cover) and they can either have inline code like this:
| |
Or they can inherit from a component class like this:
| |
| |
We’ll use the latter approach as I prefer to separate out processing logic so it could be testable, and also having a “code behind” gives me fond nostalgia to ASP.NET WebForms. 😉
Here’s what our Component razor will look like:
| |
And let’s break down some of the interesting things, starting with the <form>.
| |
This form will submit the search but we don’t want it to go to a server, we want to wire it up to something within our WASM application, and to do that we bind the appropriate DOM event, which is onsubmit, and give it the name of a public method on our Component. We’ll also need to access the search term entered and for that we’ll use two-way data binding to a string property, via the @bind attribute, providing the name of the public property. With this in place Blazor will take care of wiring up the appropriate DOM events so that when the user types and submits to right “backend” is called.
When the search runs it’ll update the SearchResults collection which we can then use a foreach loop over:
| |
Here we’re injecting values of our properties into attributes of DOM elements, referencing the .NET objects with the @ prefix, in the same way that has been done with Razor for ASP.NET MVC.
And with that our UI is ready so we can head over and create our “code behind”.
Step 4 - Creating Our Component
Our Component is going to be written in F# and living in the Search.Site class library, so we’ll need to add some NuGet packages:
| |
Note: We’re using the preview packages here, just like we’re using the preview .NET Core build, but ensure you use the latest packages available, and they match the ones in the UI project.
I’m also going to include the excellent TaskBuilder.fs package so that we can use F# computation expressions to work with the C# Task API.
| |
We’re going to need a complex type to represent the results from our search so we’ll add a file, SearchResult.fs (I use Ionide so it automatically adds it to the fsproj file), and create a Record Type in it:
| |
Now let’s create a file called SearchComponent.fs and we can start scaffolding our component:
| |
And back to Index.razor in the Blazor project we can add @inherits Search.Site.SearchComponent so our Component uses the right base class.
It’s now time to start up the server, let’s do it in watch mode so we can keep developing:
| |
Once the server is up you can navigate to http://localhost:5000 and see the initalisation message!
Step 5 - Integrating Lucene.NET
Our WASM application my be up and running but it’s not doing anything yet and we want it to connect to Lucene.NET to allow us to search. Before we do that though I just want to cover off some of the basics of Lucene.NET.
Lucene.NET 101
Lucene.NET is a port of the Java Lucene project which is a powerful, highly-performant full-text search engine. With it, you can create search indexes, tokenize “documents” into it and search against it using a variety of query styles. The .NET port is an API-compatible port, meaning that the docs for Lucene-Java apply to Lucene.NET. There are a few core pieces that we need to understand to get started.
Lucene centres around a Directory, this is the location where the search index is stored, what you write to with an IndexWriter and query against with an IndexSearcher. Everything stored in Lucene is called a Document which is made up of many different fields, each field can be tokenized for access and weighted differently to aid in searching. When it comes to searching you can query the document as a whole, or target specific fields. You can even adjust the weight each token has in the query and how “fuzzy” the match should be for a token. An example query is:
title:react tag:azure^5 -title:DDD Sydney
This query will match documents that contain react in the title or azure in the tags excluding any that contain DDD Sydney in the title. The results will then be weighted so that any tagged with azure will be higher up the results list. So you can see how this can be powerful.
If you want to learn more about Lucene I’d recommend checking out the Lucene docs and some of my past posts as it’s much more powerful a tool than I want to cover here.
Creating Our Index
We need to add some packages to our project so that we can start using Lucene.NET and we’re going to use the 4.8 release as it supports netstandard2.0, and thus .NET Core. At the time of writing, this is still in beta and we’re using the 4.8.0-beta00006 release. We’ll start by adding the core of Lucene.NET and the analyzer package to Search.Site:
| |
To create our index we’ll need to create a directory for Lucene.NET to work with, now normally you would use FSDirectory but that requires a file system and we’re running in the WebAssembly sandbox so that’ll be a problem right? It turns out not, for the System.IO API’s used by Blazor (via the mono runtime) map to something in memory (I haven’t worked out just how yet, the mono source code is a tricky thing to trace through).
Note: You may notice that we’re going to hit up against an issue, everything is in memory. This is a limitation of how we have to work, after all, we’re still in a browser, but it does mean the index is created each page load. In a future post we’ll look at how to do some optimisations to this.
The entry point that we want to use for our Component is the OnInitializedAsync as it gives us a convenient point to create the directory and start loading our JSON file into the index, but how will we get the JSON? Via a fetch of course, but since this is .NET, we’ll use HttpClient and inject that as a property of the Component:
| |
Now it’s time for the fun to start, let’s build an index! I’m unpacking the JSON into a type defined in F# that maps to the properties of the JSON object and it’s an array so we can iterate over that.
Note: The System.Json package doesn’t work well with F# record types so I’m using FSharp.SystemTextJson to improve the interop. I’ve also created a custom converter for DateTimeOffset that handles some invalid dates in my post archive.
| |
This might look a bit clunky but essentially it is creating a Document, adding some fields and returning it cast a IEnumerable<IIndexableField> before creating an analyzer and a writer to write the index.
Let’s look closely at a few lines:
| |
Here we’re creating the field to store the title of the post. It’s created as a TextField, which is a type of field in Lucene that contains multiple terms that need tokenization. This is different from the StringField which expects the value to be treated as a single token (and why we use it for the tags). This means we can search for each word in the title “Implementing Search in Blazor WebAssembly With Lucene.NET” rather than treating it as a whole string.
You’ll also notice that this field is stored, denoted by Field.Store.YES, compared to Field.Store.NO of the content. The difference here is on the retrievability of the value. A stored value can be retrieved by a query whereas a non-stored value can’t be. A stored value is also going to take more space up and be slower to access, which is why you want to be selective about what you store in the original format.
Lastly, we’re setting a Boost on this field of 5, meaning that any term that’s found in this field is 5 times more relevant than the same term in a different field. Boosting the field means that if you were to search for react OR azure documents that contain either in the title will be ranked higher in the results than ones that only contain those terms in the content.
Let’s look at storing the tags:
| |
This time we’ve used StringField since it’s only a single term but we aren’t boosting, although it seems like we should, tags are pretty important. Since we’re using the StringField which doesn’t get analyzed we can’t boost it, instead, we’ll boost at search time.
Once all the posts are turned into documents it’s time to write them to the index and that’s what these 4 lines do:
| |
When writing a document to an index the fields are analyzed so Lucene knows how to build the index. We’re using the StandardAnalyzer here which combines a few common scenarios, ignoring “stop words” (this, the, and, etc.), removal of . and ' and case normalisation. I have a bit more in-depth information in my post about Lucene analyzers, but this one works for common scenarios on English content. With the analyzer we create an IndexWriter and write the documents to the index, creating something we can search against.
Step 6 - Searching
With the index being created when our Component is loaded the last thing we need is to handle the search and that means filling out the Search function. We’re also going to need another NuGet package for constructing the query:
| |
And now construct the query:
| |
Well then, that’s… long… let’s break it down. We start with a match expression to ensure there was something to search on, if there isn’t then just ignore, otherwise we need to construct a query.
| |
Since users won’t understand the structure of our search index internally we want to make it easy for them to search and to do that we’re using a Query Parser, in particular, the MultiFieldQueryParser which helps with the construction of queries across multiple fields. After specifying the Lucene version to use we then provide an array of fields to search against (title, content, tag and desc) and then provide a weight for each of the fields. Remember earlier I said we could weight tag because it wasn’t tokenized, well this is how we weight it, by providing a dictionary (IDictionary<string, float>) where the key is the field and the value is the weight. Annoyingly we need to provide each field regardless of whether we want to boost it, but that’s how the API works.
Lastly, we set the default operator for the parsed queries to be an OR operator rather than AND, allowing us to cast a wider nett in our search.
With the parser ready we can search the index:
| |
Here we’ll use a custom sorter that sorted first on the “score” (how good a match was it) then by the date (newest posts are more relevant). Using a custom sorter does pose a challenge though. When a search is done you receive a score for each document, this is produced by quite a complex algorithm (taking into account term count, boosts, etc.) and the bigger the number the higher in the results it’ll appear. But when a custom sorter is applied the score is no longer the only value of importance and it means if you want to show a “% match” for the document, it’s not so straight forward. So let’s have a look at how we build the results and their scores.
| |
Initially we go through all the matched docs (well, the top 20 which we limited to) and cast them to FieldDoc then extract the first field value, which is our score (cast as a float32) (we know that will be the score because of its position in the sorter) and find the largest one.
Next we can iterate through the matched documents which gives us an object with the document it, hit.Doc, that we’ll ask the searcher to retrieve the document using. We have to ask the searcher because the document ID is in the context of the query performed.
With the document we can extract the stored fields, build our search results object and return it to the UI.
Search In Action
We’re done now!
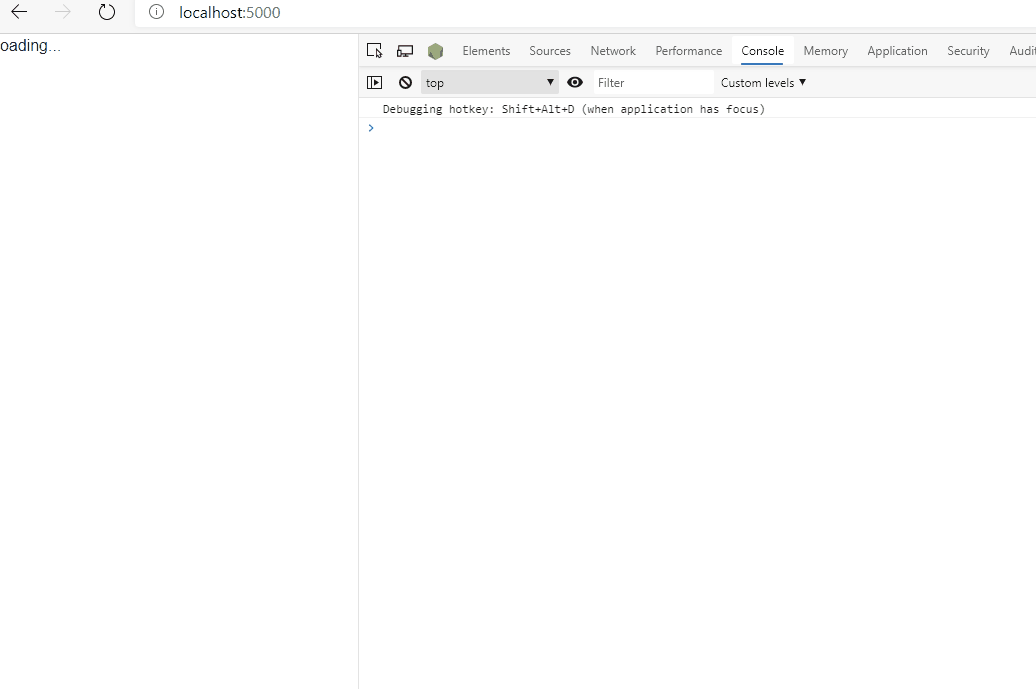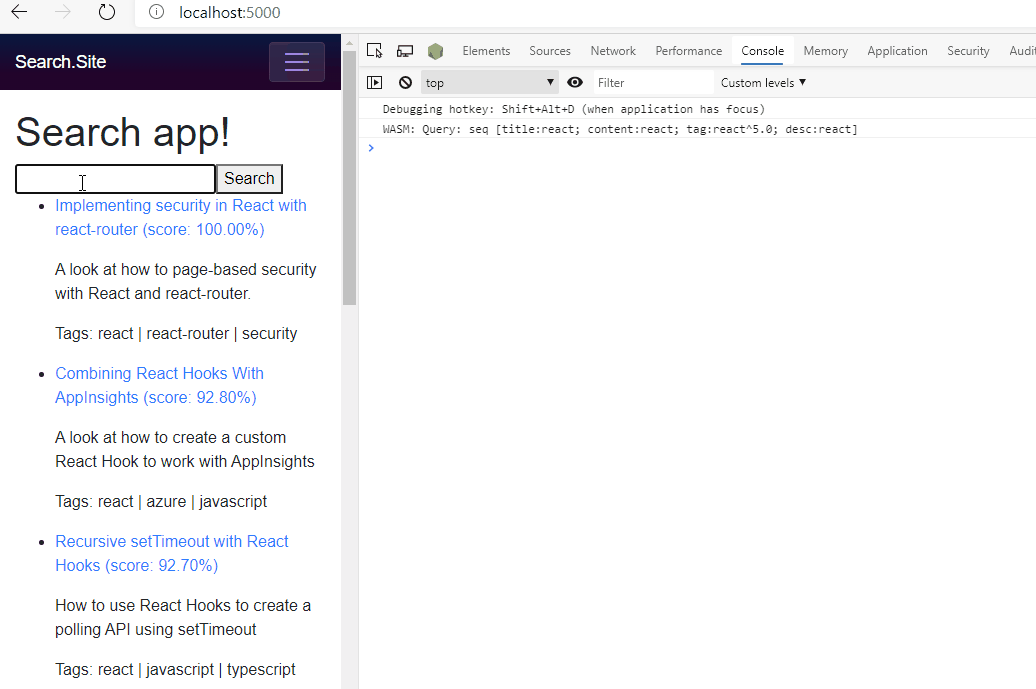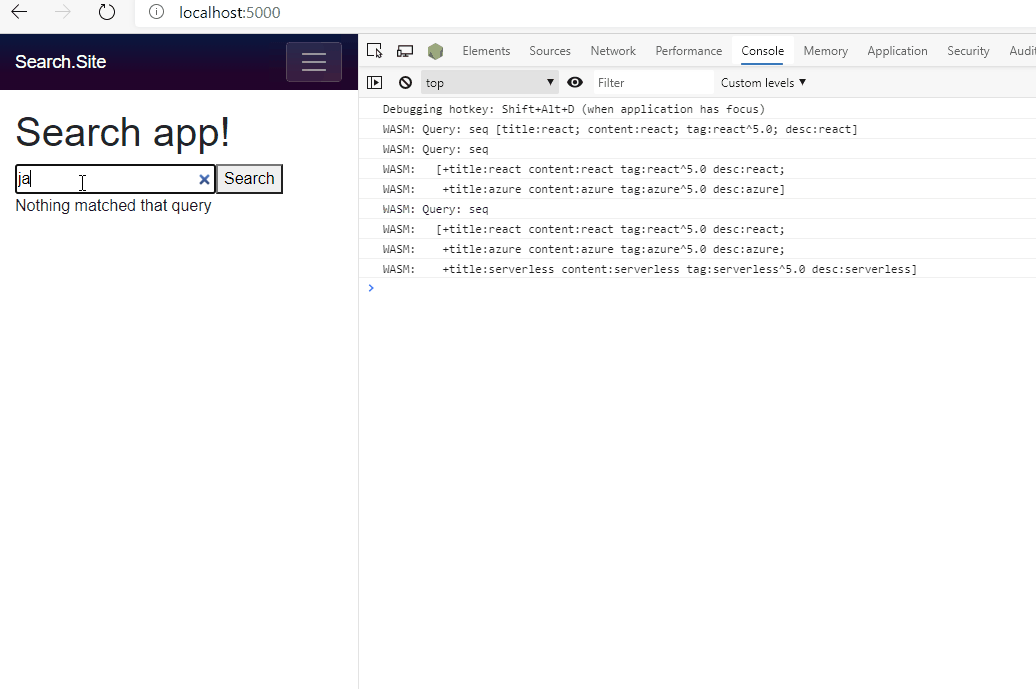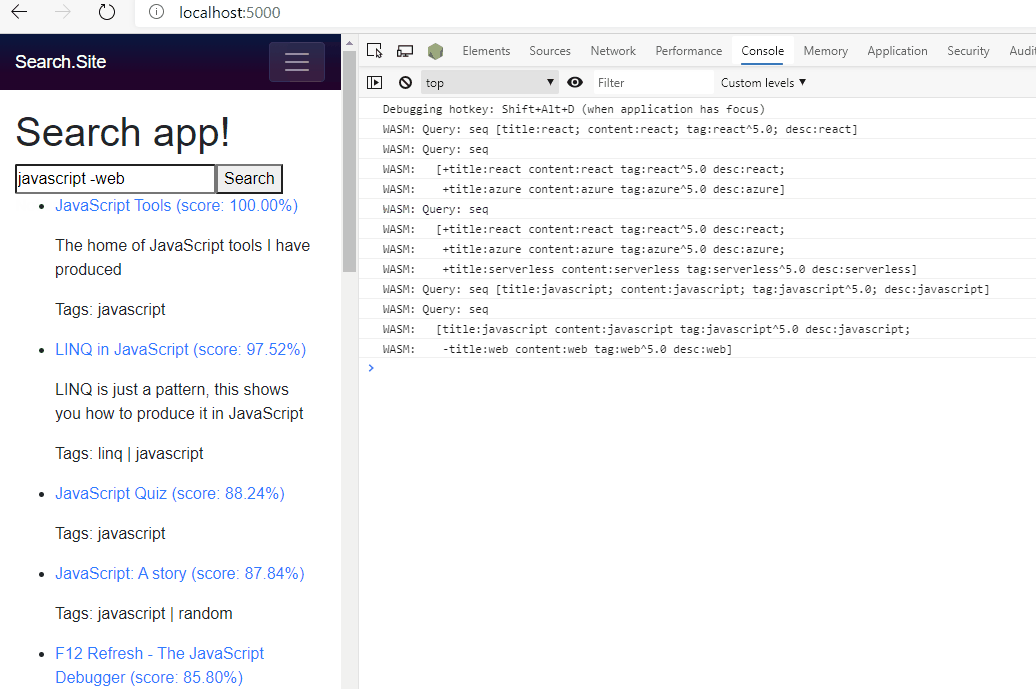
For this demo above I’ve kept a debugging message where I dumped out the query that was parsed to the console so you can see what was being sent to Lucene.NET to produce the results.
Conclusion
I have to admit that when I started trying to build this I didn’t expect it to work. It felt like a rather crazy idea to use what is quite a complex library and compile it to WebAssembly, only to have it “just work”.
But as this post (hopefully) demonstrates, it’s not that hard to add search to a Blazor WebAssembly project, I spent more time trying to remember how to use Lucene.NET than I did building the application!
And do you know what’s cool? I now have search on my site now!
The way that I have it built is a little different to what I’ve described above, but I’ll save some of those advanced concepts for the next post.