One of the things I like most about Azure Static Web Apps, aka SWA, is that it generates you a GitHub Actions workflow file for you, ensuring that you’ve got a CI/CD pipeline that will deploy the code as you push changes, making repeatable deployments happen by design. If you’re not using GitHub Actions, no problems, you can use Azure Pipelines, GitLab, Bitbucket, or the newly release cli deploy command and achieve the same repeatable workflow rather than falling back to copying files to a remote server.
For this post, I’ll be using GitHub Actions, as that’s what I’m using for my blog (which this article is based off), but the patterns will be the same for other build platforms.
To refresh, or for those who aren’t familiar with SWA, here’s the job that gets generated which will build and deploy your application to Azure:
| |
The really important part of this is the Build And Deploy job as it’s responsible for two tasks, building the front end (and Functions API if it exists), then uploading it to Azure.
While this workflow will cover many use cases, it’s possible to want to grow beyond it. Maybe you’re wanting to run tests as part of the pipeline, or you want to add an approval process for the deployment, or anything else that means that combining the build phase with the deploy phase can make it difficult.
Going beyond the default
Let’s look at going beyond the default, and to illustrate a complex GitHub Actions pipeline that ultimately deploys to SWA:
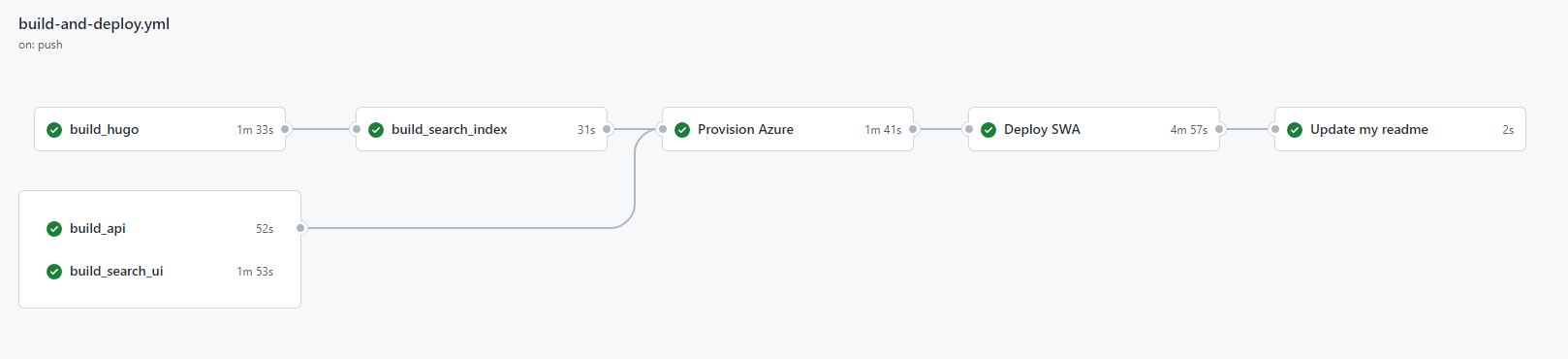
This is a picture of the workflow for my blog and it consists of seven jobs to be run with nearly 40 steps run across them all. Some of these jobs run in parallel, some are run in sequence, but all-in-all, this is how I deploy my blog.
So, why is it so complicated? Well, my website is made up for three different platforms, Hugo for the blog itself, .NET for the Blazor powered search and TypeScript for the API (which I’ll blog about separately soon). Because of this, the standard SWA action won’t work; it doesn’t know what to build!
Because of this, I have three primary parallel jobs, build_hugo, build_api, and build_search_ui and each of these will generate artifacts to be deployed. For the post, I’ll document a much simpler process, but you can view my full (and maybe overly complex…) workflow at build-and-deploy.yml.
Build first, deploy later
The first thing we’re going to want to do is split the build phase out from the rest of the pipeline. The actual steps you’ll run in GitHub Actions will depend on what you’re building, let’s go with a JavaScript application:
| |
The important part here is to know where the output will go, and in this case we’re just assuming that it’s in the build folder of this hypothetical application.
But how do we get them later? By turning them into an artifact of the job, using the actions/upload-artifact Action:
| |
This will package the output contents of our build step and upload it to the workflow that we can use later on.
Artifacts with lots of files
If you’re working with an output that will contain a lot of files, such as a node_modules folder (because it’s a non-bundled application), you might want to package them into an archive and then upload that archive (like I do with my API):
| |
This is because when uploading, it’ll do it file-by-file upload and when there’s a lot of files this can take a looooooong time (thus making builds slower), but if we create an archive, it’ll upload just a single file, which is a lot less IO.
Deploying from artifacts
Now that we’ve split out our build phase from the SWA Action, how to do we use it?
Start by defining a new job in our workflow, deploy, and add a needs section to it saying that it needs the build job to complete first, otherwise this job will run in parallel and we can’t deploy until we’ve built!
| |
Unlike the build job, we’re not going to need actions/checkout, because we’re not needing the source code for our application, we’re going to use the prebuilt artifact, which we get from actions/download-artifact:
| |
Specify anywhere that you want the artifact to be downloaded to. In this case, we’ll put it on the root of the agent, since we know it’s a new agent for this job, there’s no other files that we need to worry about.
Next up, we’ll bring in the azure/static-web-apps-deploy Action so that we can deploy to Azure:
| |
There’s two secrets needed, the GITHUB_TOKEN, which is provided by GitHub and AZURE_STATIC_WEB_APPS_API_TOKEN, which is the deployment token that’s generated when you first connect the repo to SWA, can be obtained via the portal, or via the Azure CLI (and that I was leaking in my logs, prompting this blog post).
The other parameters we need to change for the action is that we’ll set the app_location to the place relative to the ${{ github.workspace }} (which is empty in our case) and then set skip_app_build to true, since we’ve already built, all we need to do is deploy.
Summary
And with that, we have a completed, multi-stage workflow that looks like this to build and deploy SWA (I’ve excluded the triggers for simplicities sake):
| |
We’ve seen how we can use artifacts to move the output from one job to another, allowing for a clearly defined build and deploy phases within our workflow.
With this customisation, we can introduce any additional steps to the workflow that we want, such as running tests, deploying SWA with Bicep, or running parallel jobs to speed up a workflow run.
I have a much more complex form of this running my blog which you can see in my workflow at build-and-deploy.yml.
Bonus - splitting PR management
SWA will automatically generate a preview environment from a PR, and part of that requires a second job to cleanup when the PR is closed:
| |
This job is included in the generated workflow file and because of that we have some if checks on the jobs, as the workflow trigger is on PR’s but we need to selectively run jobs depending on what the event that triggered the PR is.
But we can split this up as well, so we have a “close PR” workflow that’s independent from our “build and deploy” job, and we can do that by modifying the triggers for the workflow.
Let’s start with our build and deploy workflow:
| |
This workflow will still run on PR, but it’ll only run if the PR is opened, synchronized (files are pushed to it), or reopened. This means we can remove the if check from our build job.
Next, create another workflow file and move the close_pull_request_job across:
| |
This one is only triggered on the closed event for a PR, and runs a single step to destroy the preview environment.
Sure, it means there’s an additional workflow file that you have (and some potential for duplicated code), but I prefer the cleaner view of it and that it’s clear which workflows will run when.