Continuing on from the last post in which we used Azure API Management’s (APIM) Synthetic GraphQL feature to create a GraphQL endpoint for my blog, I wanted to explore how to add a completely new field to our type - Related Posts.
Using the schema editor in APIM I added a new field to the Post type of related(tag: String): [Post!], so our type now looks like this:
| |
The way this field resolver will work is that if you provide a tag argument to related then it’ll return posts that also have that tag (while first validating that the tag is a tag of the Post), and if you don’t provide a tag argument, it’ll return all posts that have the same tags as the current Post.
Aside: I have updated the /api/tag endpoint that if you provide a comma-separated string, it’ll split those and return posts that match all those tags as it previously only supported a single tag.
Building a resolver
As this is an entirely fabricated field, we’re going to have to make a custom resolver in APIM using the set-graphql-resolver policy. The resolver is going to need two pieces of data, the tags of the current Post and the tag argument provided. As we learnt in the last post, we can get the arguments off the GraphQL request context as context.Request.Body.As<JObject>(true)["arguments"], but what about the Post?
In GraphQL, the resolver that’s being executed has access to the parent in the graph, and in our case the parent of related is the Post, and we can access that by context.ParentResult.
With that setup, we can write our resolver like so:
| |
Notice that this time the parent-type is Post not Query, and we have a slightly more complex bit of C# code that generates the URL we’ll call, applying the logic that was stated above.
Let’s fire off the request and see what we get back:
| |
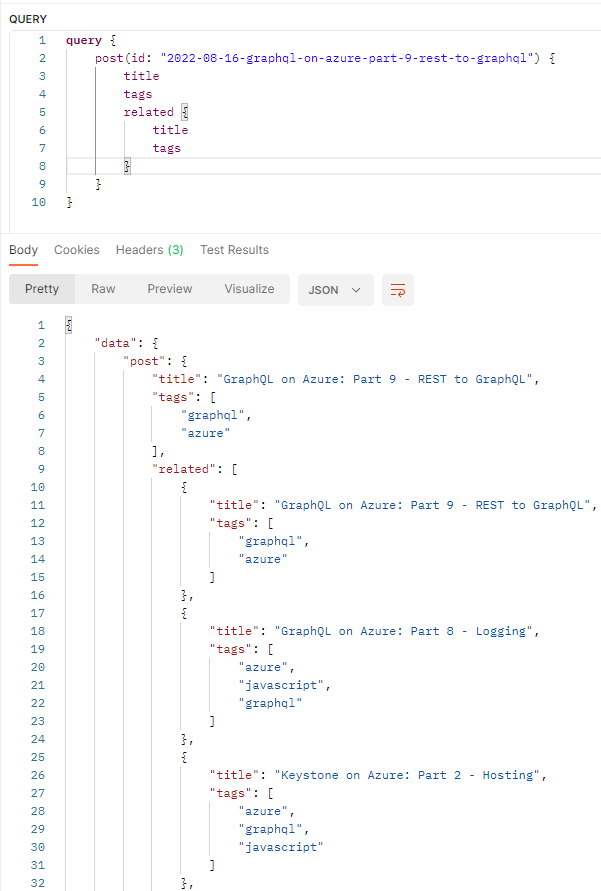
Great, it’s worked as expected… except we ended up with the post that we specified the ID of in the related posts. While that might be technically true that it’s related to itself, it’s not really what we’re expecting.
Cleaning our results
We’re going to want to do something that removes the current post from its related posts, and to do that we’re going to need to either make our REST API aware of the current Post and filter it out, or make our resolver smarter.
Going and rewriting the backend API doesn’t seem like the logical choice, after all, the point of Synthetic GraphQL is that we’re exposing non-graph data as a graph, so we probably don’t want to rework our API to be more “GraphQL ready”. Instead, we can do some post-processing in the data before sending it to the client, using the http-response part of our policy and defining a set-body transformation policy.
With set-body, we need to provide a template to execute, and this can be a Liquid template or C#. Since I’m not familiar with Liquid, but I am with C#, we’re going to stick with that. This template is going to need to get the id of the current post (which is the parent of the resolver), then iterate through all the posts from the /tags call, and remove the current post from the result set.
| |
What we see here is that we used the context.ParentResult to find the id, then parsed the current response as a JArray (since we know that the REST call returned a JSON array), then using a foreach loop, we check the posts and create a new JArray containing the cleaned result set, which we finally return as a string.
This makes our whole resolver look like this:
| |
Let’s make the GraphQL call again:
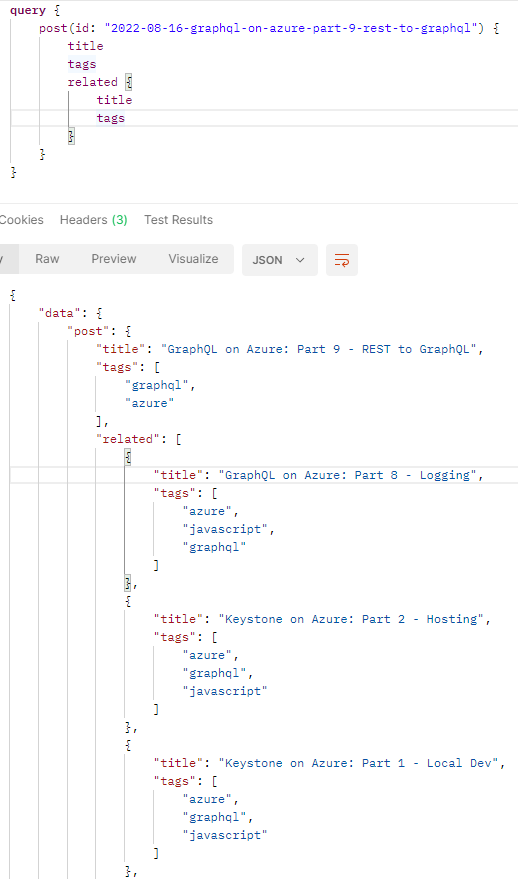
Fantastic, we’re now only getting the data that we expect.
Summary
This post builds on the last one in how to use Synthetic GraphQL to create a GraphQL endpoint from a non-GraphQL backend, but we took it one step further and created a field on our GraphQL type that doesn’t exist in our original backend model. And this is what makes Synthetic GraphQL really shine, that we can take our backend and model it in the way that makes the most sense for consumers of it in a graph design.
Yes, it might not be as optimised as if you were writing a true GraphQL server, given that with this particular example doesn’t optimise the sub-resolver calls, but that’s something for a future post. 😉