
I’m really excited because today we launched the first public preview of Data API builder for Azure Databases or DAB for short (the official name is a bit of a mouthful 😅).
The important links you’ll need are:
What is DAB
DAB is a joint effort from the Azure SQL, PostgreSQL, MySQL and Cosmos DB teams to provide a simple and easy way to create REST and GraphQL endpoints from your existing database. Now obviously this is something that you’ve always been able to do, but the difference is that DAB does it for you (after all, that’s the point of this series 😜) so rather than having to write an ASP.NET application, data layer, authentication and authorisation, and so on, DAB will do all of that for you. Essentially, DAB is a Backend as a Service (BaaS) and this makes it easier to create an application over a database by removing the need to create the backend yourself.
Quick note: DAB doesn’t support REST for Cosmos DB as Cosmos DB already has a REST API.
How does DAB work
DAB is going to need a data schema that describes the entities you want to expose. In the case of a SQL backend, DAB will inspect the database schema and allow you to expose the tables, views and stored procedures as endpoints. With a NoSQL backend (currently Cosmos DB NoSQL) you need to provide a set of GraphQL types which define the entities you want expose, since there’s no database schema to work from.
You’ll also provide DAB with a config file which acts as a mapping between the data schema and how you want those entities exposed. In the config file you’ll define entities you want to expose (so you can pick and choose what you want to expose from the available schema), access control and entity relationships. If you’re working with a SQL database and have views or stored procedures, you can define how they will be exposed.
With this information DAB will then generate the appropriate REST endpoints for each entity with REST semantics on how CRUD should work, as well as a full GraphQL schema, including queries for individual items, paginated lists (with filtering) and mutations (create, update and delete).
Your first DAB instance
Sounds cool doesn’t it? Well, let’s go ahead and make a DAB server. The first thing we’ll need to do is install the DAB CLI:
| |
The CLI is used to help us generate our config file, but also to run a local version of DAB. I’m going to use DAB with a Cosmos DB backend, just to show you how to go about creating a data schema for Cosmos, so you’ll either need a local emulator or deployed Cosmos DB instance (I like to use the cross-platform emulator in a devcontainer).
Let’s start by initialising the config file:
| |
This will generate you a config file like so:
| |
Since this is Cosmos DB and we don’t have a database schema we can work with, we’re going to need to create some types in GraphQL for DAB to use:
| |
This looks pretty standard as far as a GraphQL type is concerned, with the exception of a @model directive that’s been applied to the type. This directive is required to tell DAB that this is a type that we want to generate a full schema for (queries and mutations), and not a type that is a child of another type (in the case of a nested JavaScript object).
With our schema defined, we have to tell DAB how to retrieve documents from Cosmos that match that type, and that’s what the entities field in the config file is for. Let’s use the CLI to define a new entity:
| |
This command is defining a new entity called Question, specifying that the collection (source) in Cosmos DB is questions and that we want to allow anonymous access to all operations on this entity. I’m being pretty lazy on the security, but if you want to do it properly you can define different roles and the access they have (create, read, update or delete) to the entity.
With this added our config file now looks like this:
| |
With the config file complete we can now the server:
| |
Now we can load up the GraphQL endpoint, https://localhost:5001/graphql, in your preferred GraphQL IDE (I like to use Banana Cake Pop):
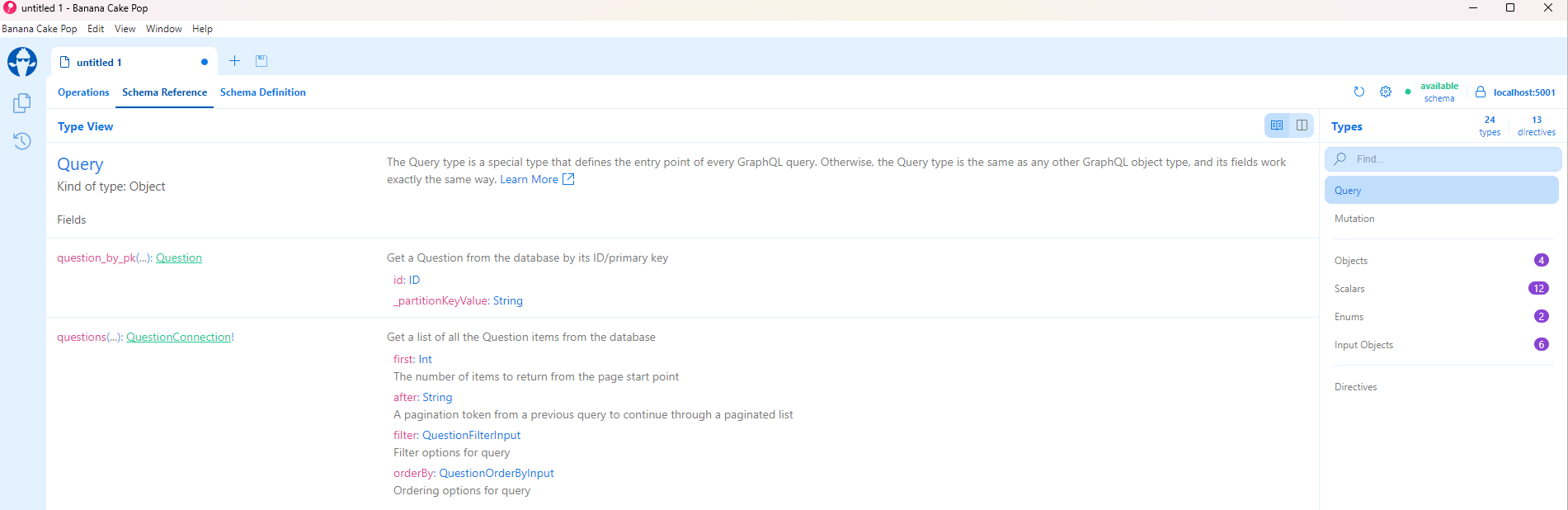
You’ll then see the whole GraphQL schema that was generated from the config file and GraphQL types provided:
It’s really cool, we have queries just magically generated for us!
| |
This means we could write a query like this:
| |
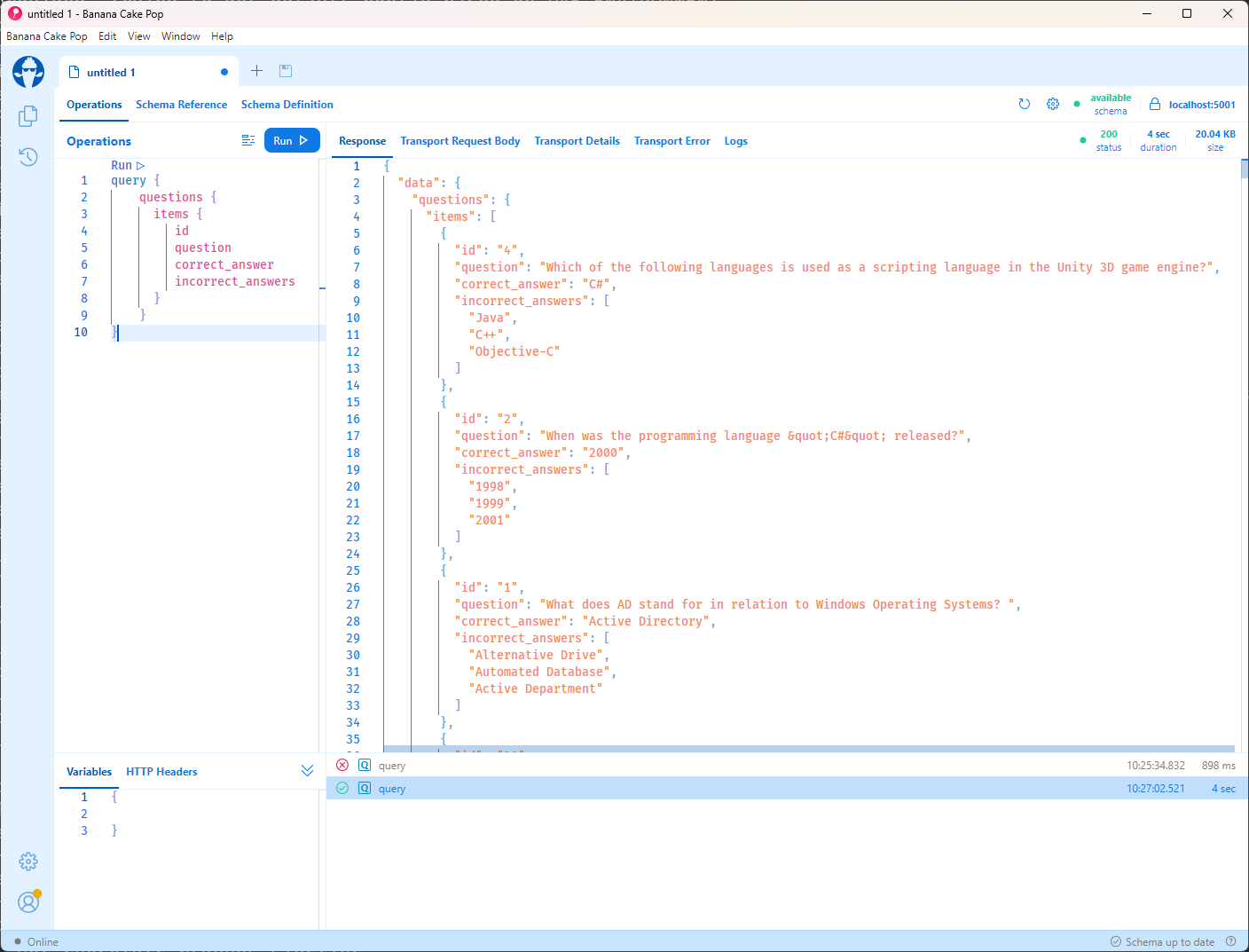
And when executed it’ll return all the documents:
You can even write complex filter queries that take a subset of the results:
| |
Which will then give us an output such as:
| |
The endCursor is a token that can be used to get the next page of results, using the after input field, and the hasNextPage flag tells us if there are any more pages to get.
Conclusion
In this post we’ve looked at how to use GraphQL as a service on Azure, using the Data API builder project. It’s a really cool project that allows you to quickly get up and running with a GraphQL API (or REST if that’s your preference, but this series is GraphQL on Azure, not REST on Azure 😝).
With a few commands we can scaffold up DAB, define what the data schema we want to export looks like, connect to an existing database and then start serving up data.
Go check out the official announcement, and the GitHub repo, the docs and the samples and give it a try!