When we explored Chat Completions in Part 3 we used the asynchronous API to call our model, but it’s still somewhat a blocking call in that we wait for the model to generate a response before sending to the client. This is how we would traditionally get data back to a client from a data source, since the data source we’re requesting from, like a database, will have all the data we need, it just has to “find it”. But when working with an LLM, it’s a bit different, we’re generating the data (response) on the fly, and depending on the complexity of the model, it can take a while to generate a response - and the longer it takes to generate, the more likely the user is going to assume something has been unsuccessful.
Streaming Response
Enter streaming responses. This is the experience that you’re more likely to be familiar with using tools like ChatGPT, Bing Chat, GitHub Copilot Chat, and so on. It’s where you receive the response back in chunks, as they’re generated, rather than waiting for the entire response to be generated before sending it back to the client.
For a streaming response we will call the GetChatCompletionsStreamingAsync method on our OpenAIClient object, which returns a Response<StreamingChatCompletions>. From here, everything is asynchronous iterations, which we can use the await foreach to step through:
| |
First, we’ll iterate over the IAsyncEnumerable<StreamingChatChoice> which will give us each StreamingChatChoice that has been returned from the model. Remember, this defaults to one, but you can request a higher maximum, although that doesn’t guarantee you’ll get more than one.
As we iterate over the StreamingChatChoice we request a message stream using GetMessageStreaming that returns an IAsyncEnumerable<ChatMessage>. Iterating over this IAsyncEnumerable gives us each message chunk back from the model, which we can extract the content and send to the client. This is only the chunk from the last chunk, so our client will need to treat it as an append operation, not a replacement, which is why I’m using Console.Write here to continue on from the last point in the console.
Let’s see our notebook sample in action:
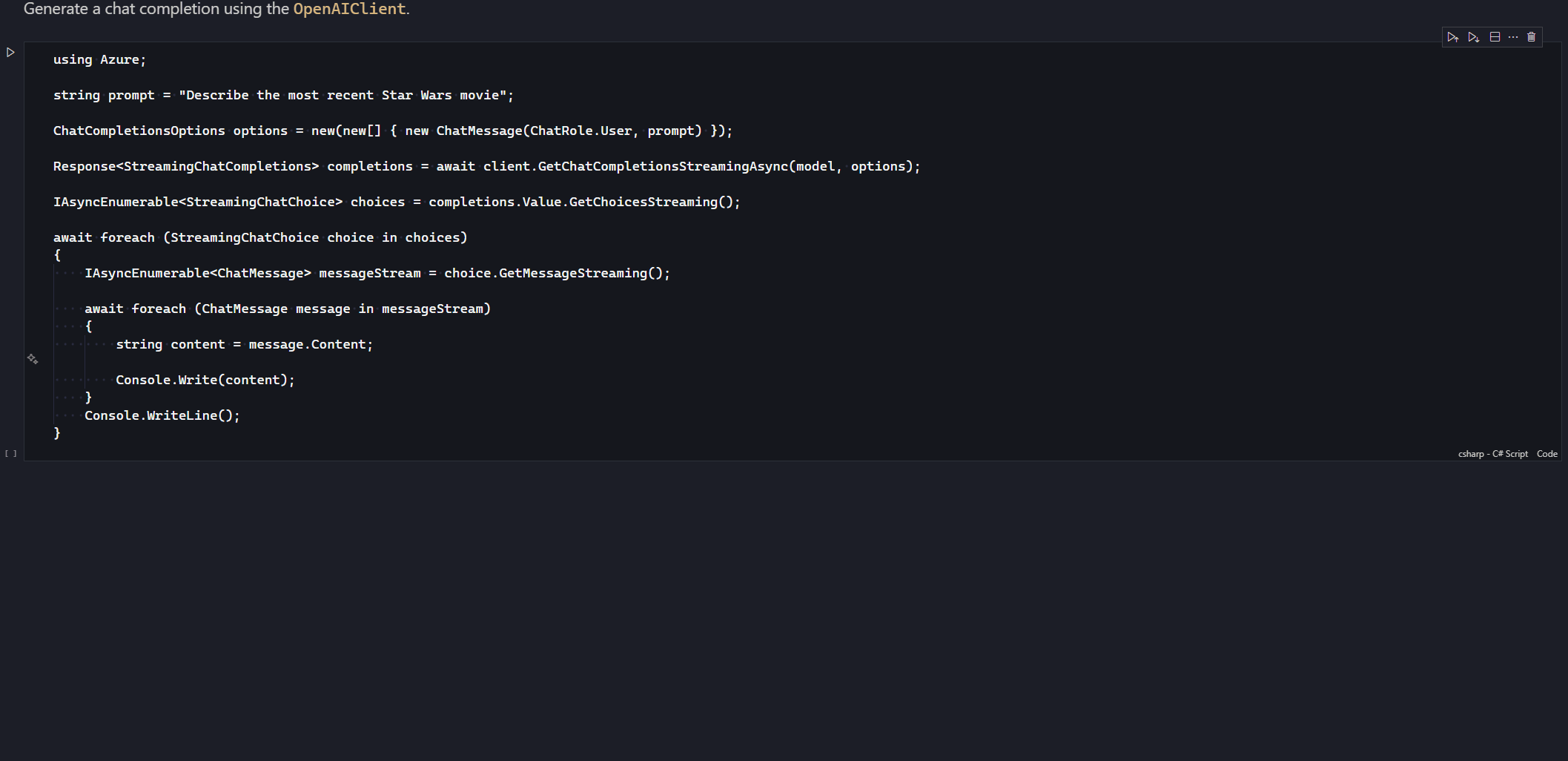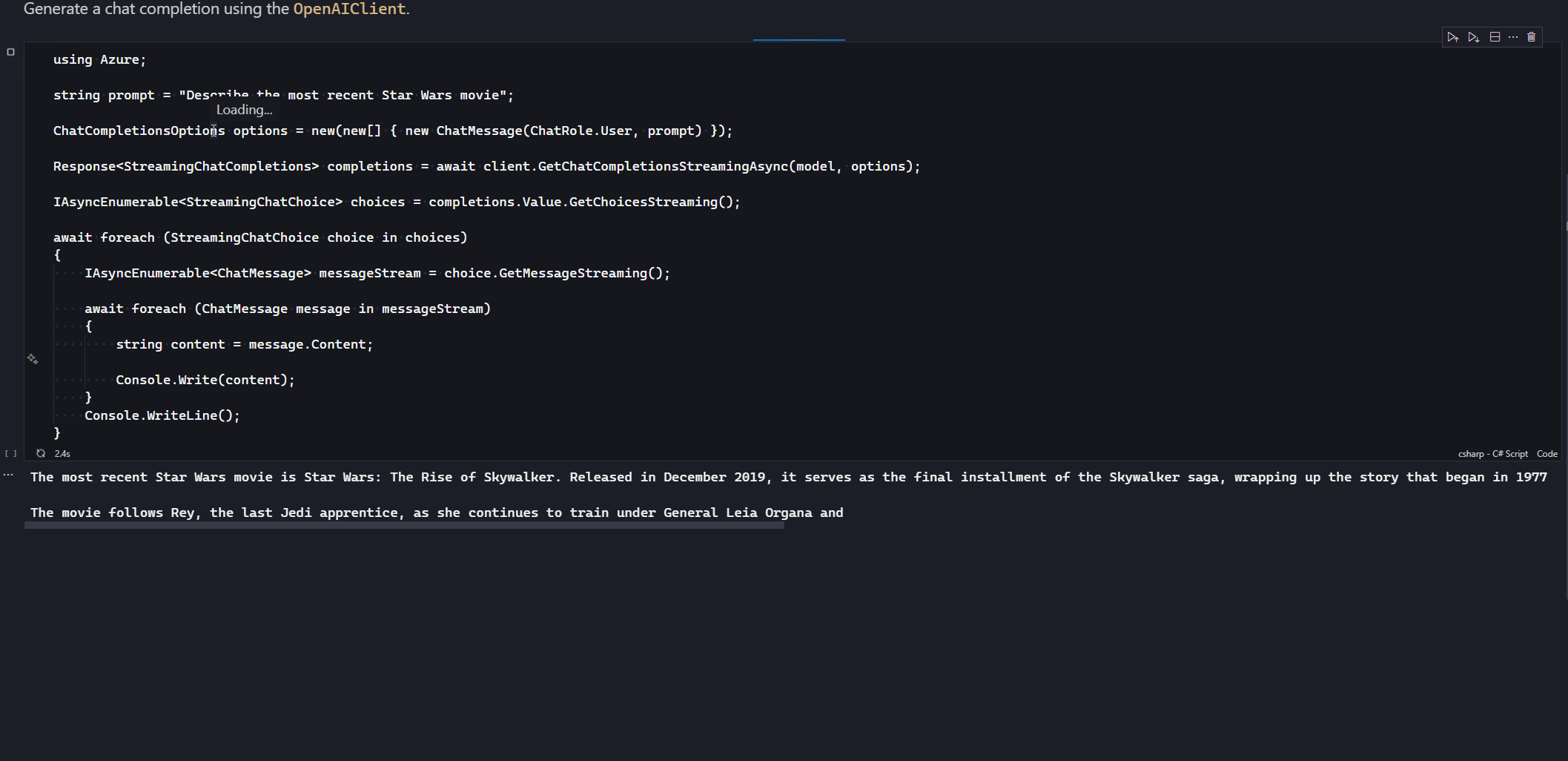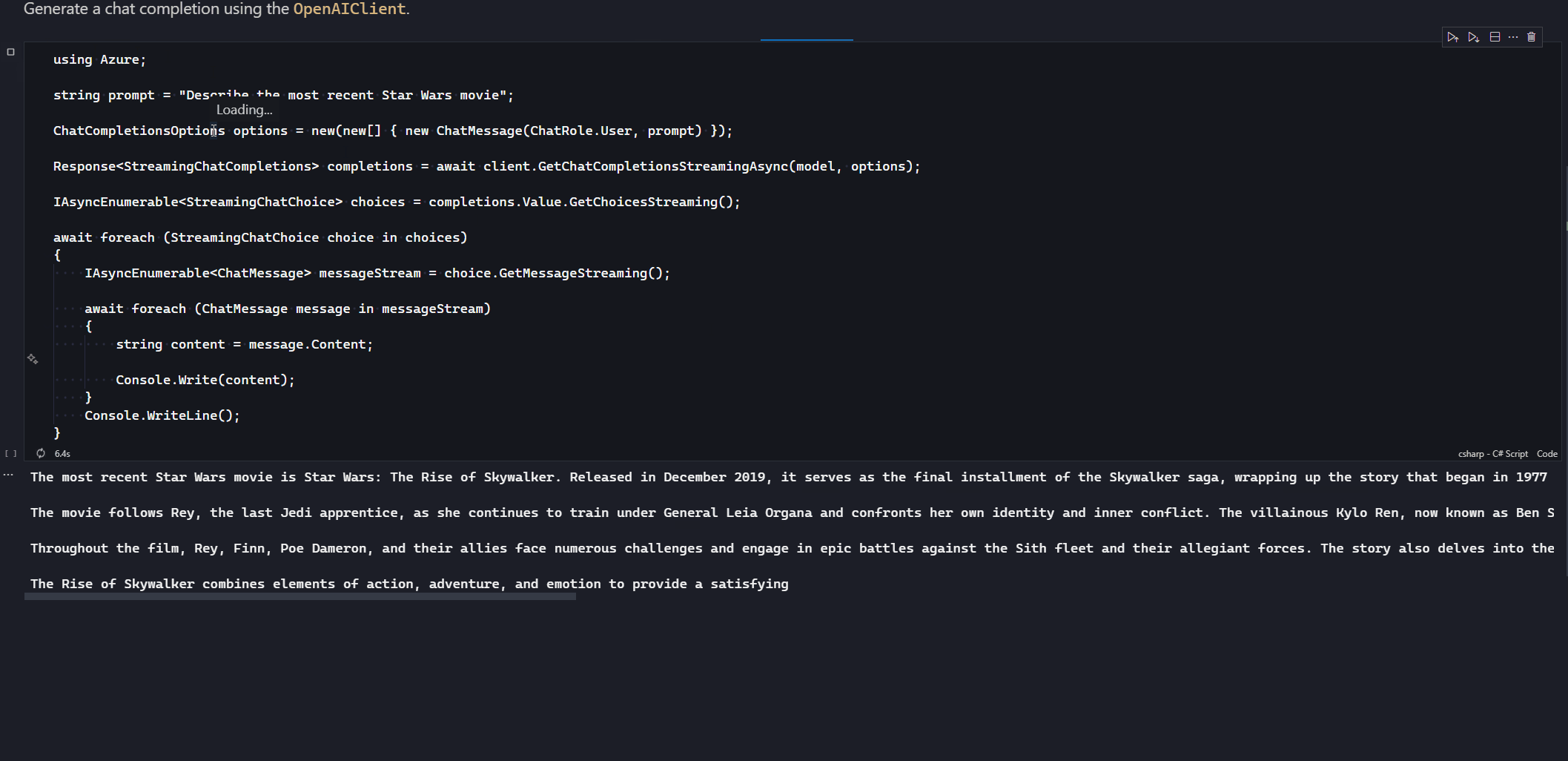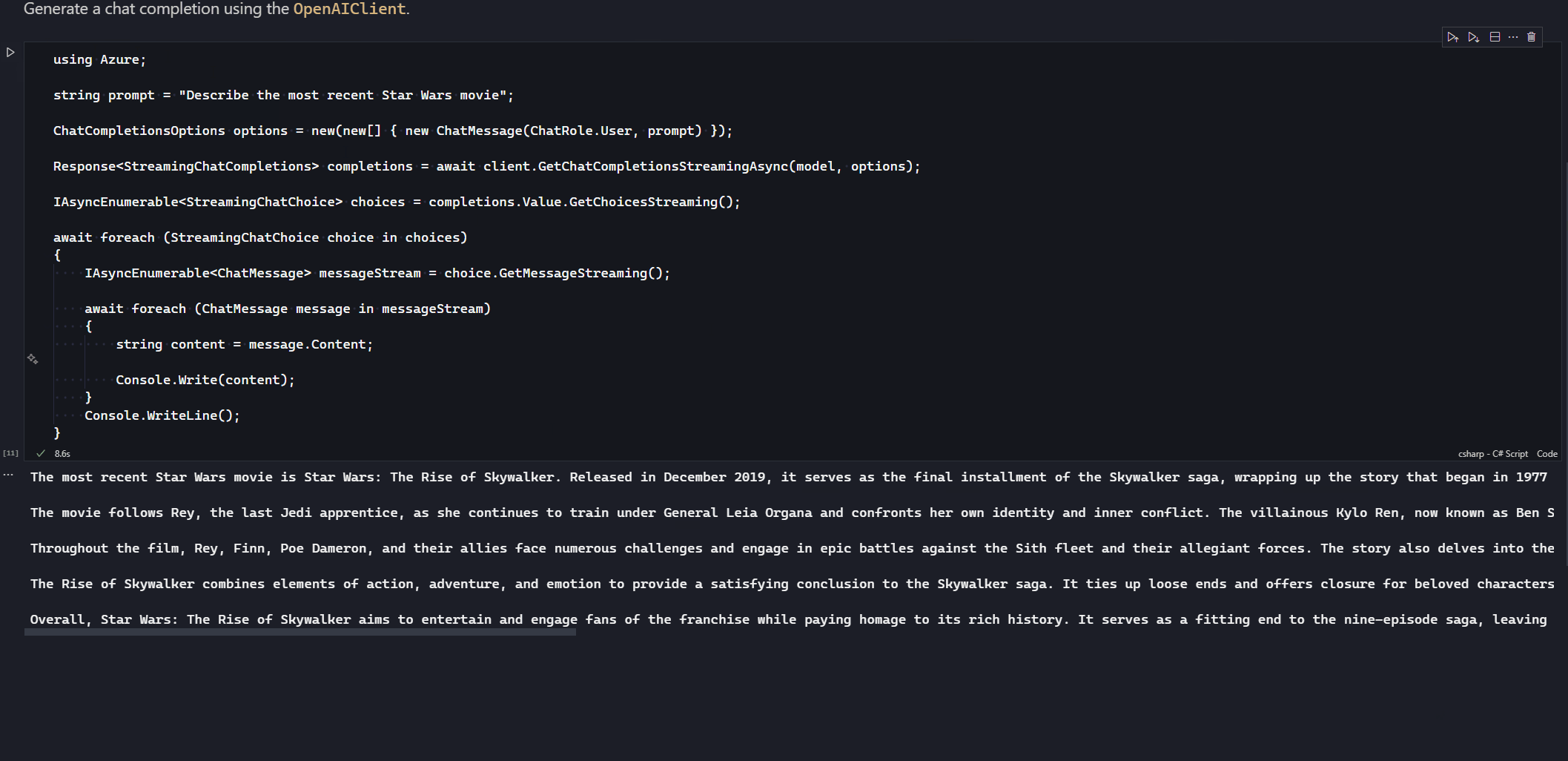
Here you see the chunks getting written out as they come back from the model. It’s worth noting that the response times are non-deterministic, so it could be that it’s very quick, as is the case in the above demo, or it might take a whole lot longer if the response is a lot more complex to generate.
Conclusion
That’s it, we’ve seen how we can use streaming as an alternative way to get the response back from our model and send it to a client - a simple Console.Write statement in this case. The way you send the stream to the client will depend on what kinds of clients are being supported, but some options to consider are using web sockets (Azure SignalR Service is a good option there) or chunked HTTP responses.
Next time we’ll start delving a bit more into aspects of prompt engineering and how we can use that to get better responses from our models.